Is the sample application for the HTMLParser.
If you try it, it’s as easy to goto Yahoo Finance, cut and paste the URL for the symbol you want to extract the daily price history for, and search for the first record, and double click to open the extractor window, and drag and drop the tags you wish to extract.
I play fantasy football, so my example will be to extract fantasy football stats from my favorite fantasy football site. You should have a programmer’s understanding of possibility of matches in HTML that were not intended, and how to mitigate that. As a hint, you can usually handle that by terminating on the close tag of the region your code is actually interested in. But if you are using the Dll code, I assume you have the requisite sophistication.
To try it out yourself, before you try to deconstruct the code.
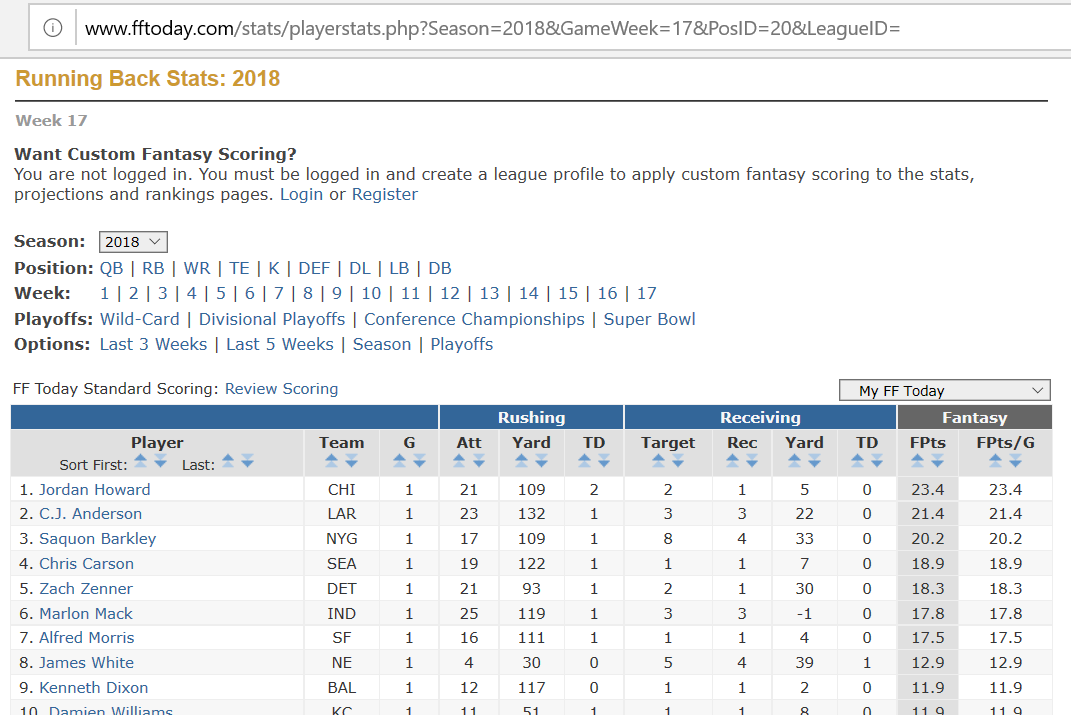


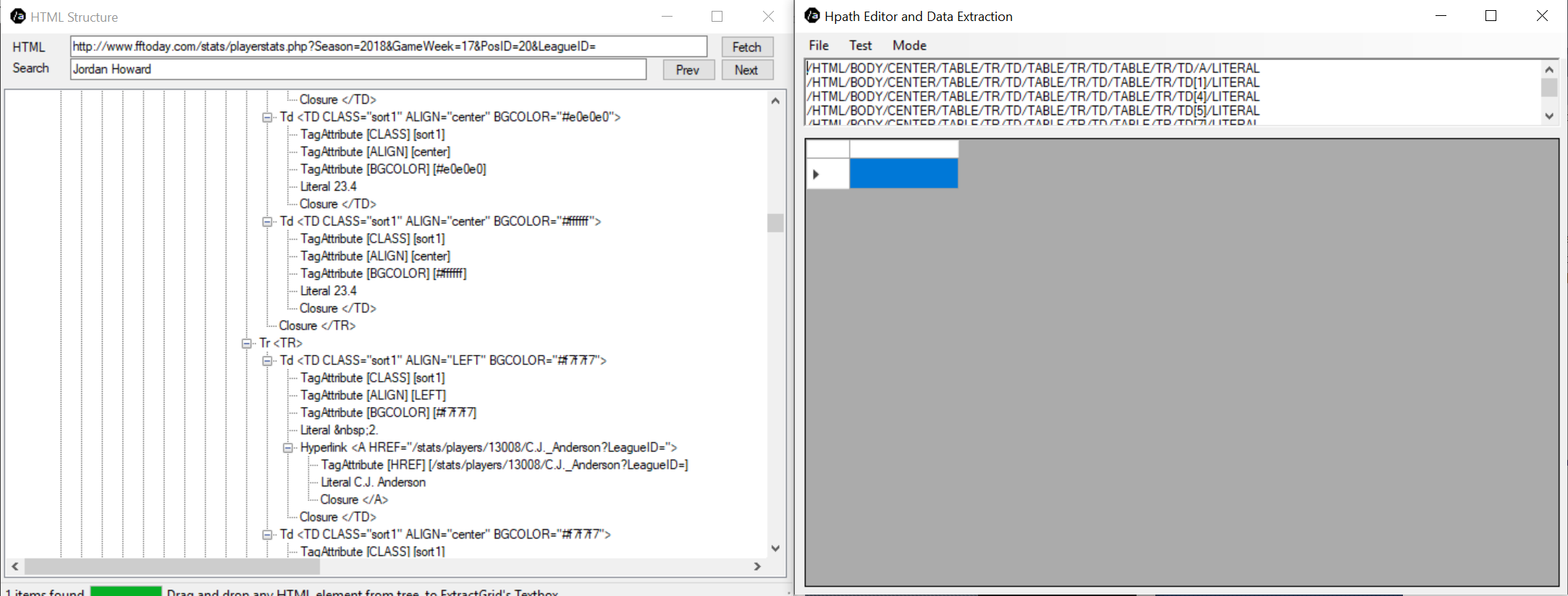
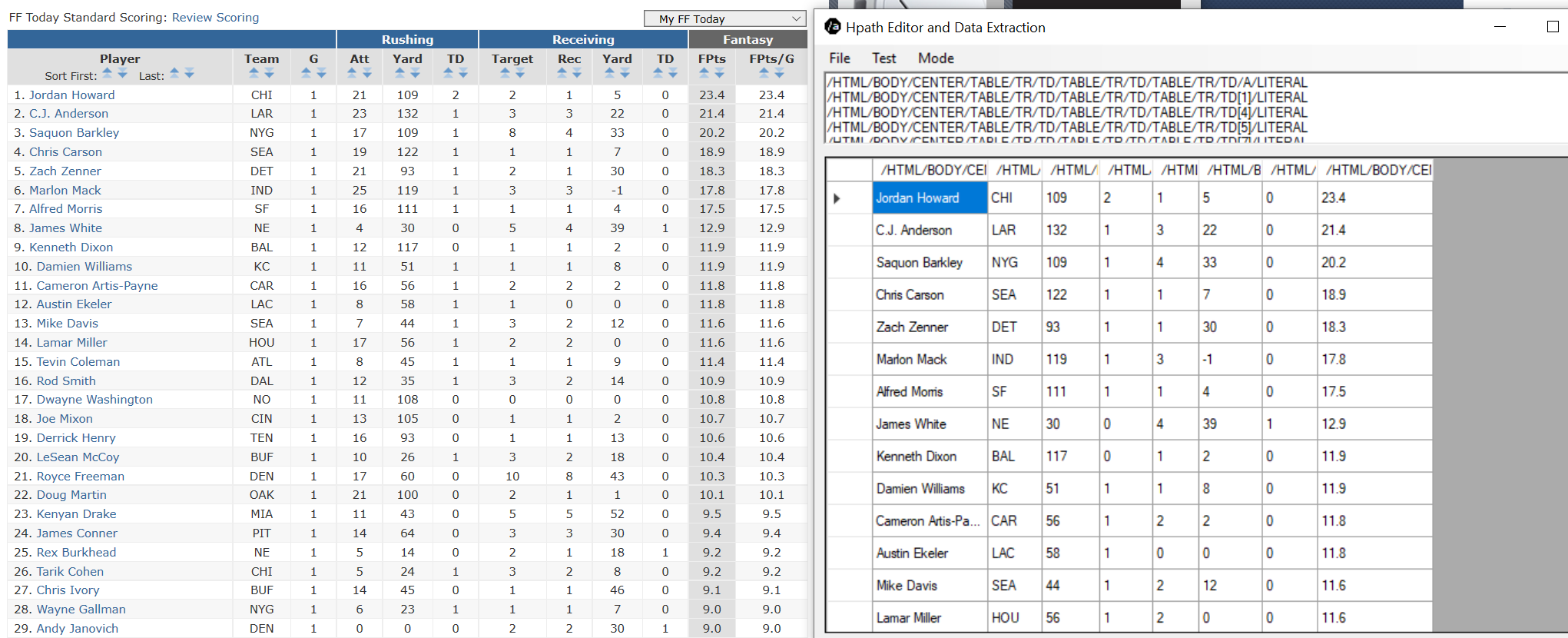
It is that easy to use… The HPath expressions I use, to cut and paste in code, where I use the HTML Parser. I rarely use this project, except to view what the results will be, before I code it somewhere.
Good luck. Post comments. Let me know if this helped to decipher the project. I’ll cleanup the code…. never. I haven’t had to refactor, so I probably will never cleanup that mess. Hell, the hpath project was mostly just so I can post the project on github, and not have a ton a criticisms that the project makes no sense.